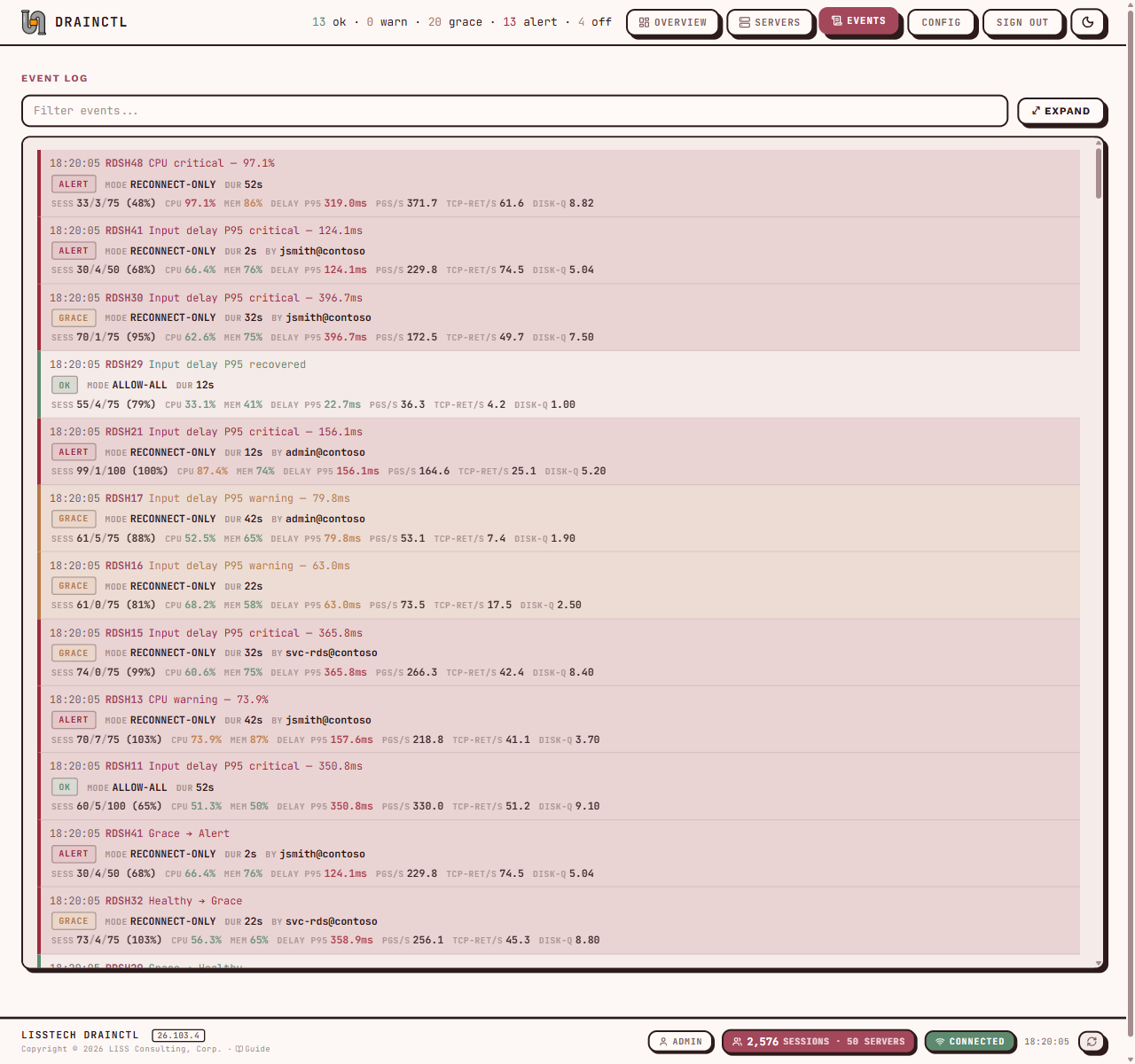
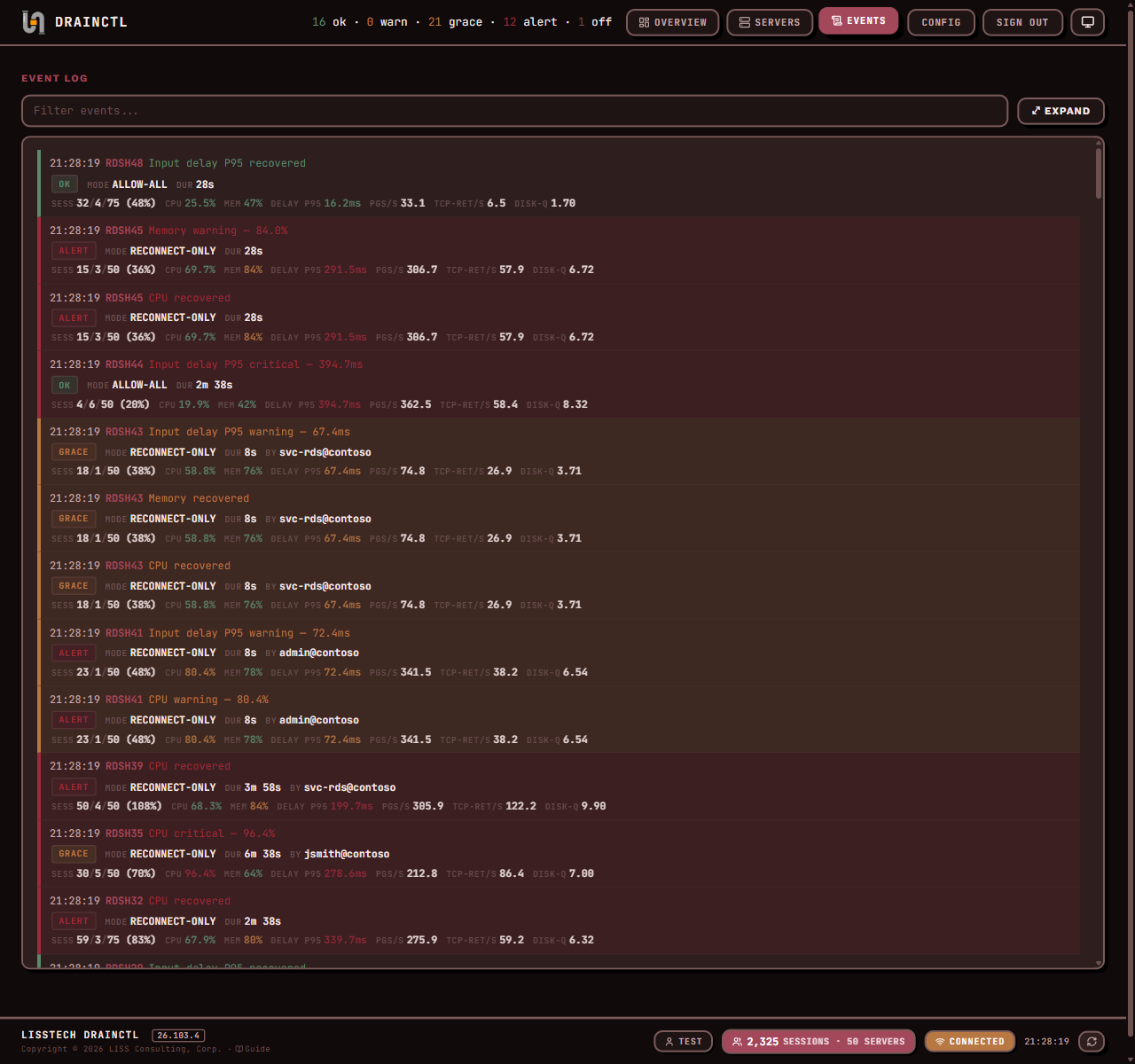
Someone disabled new connections
at 2 AM. You'll know who.
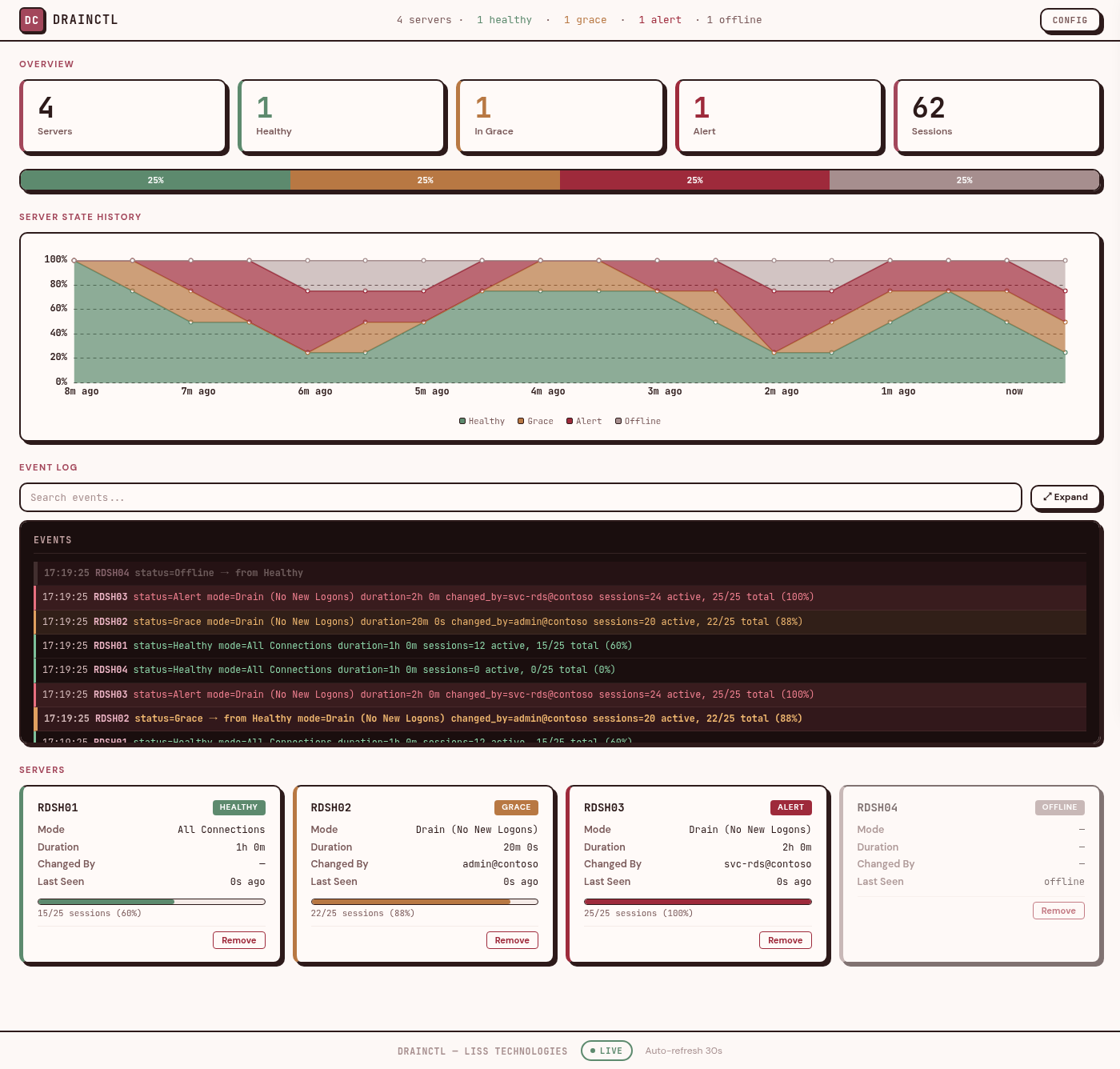
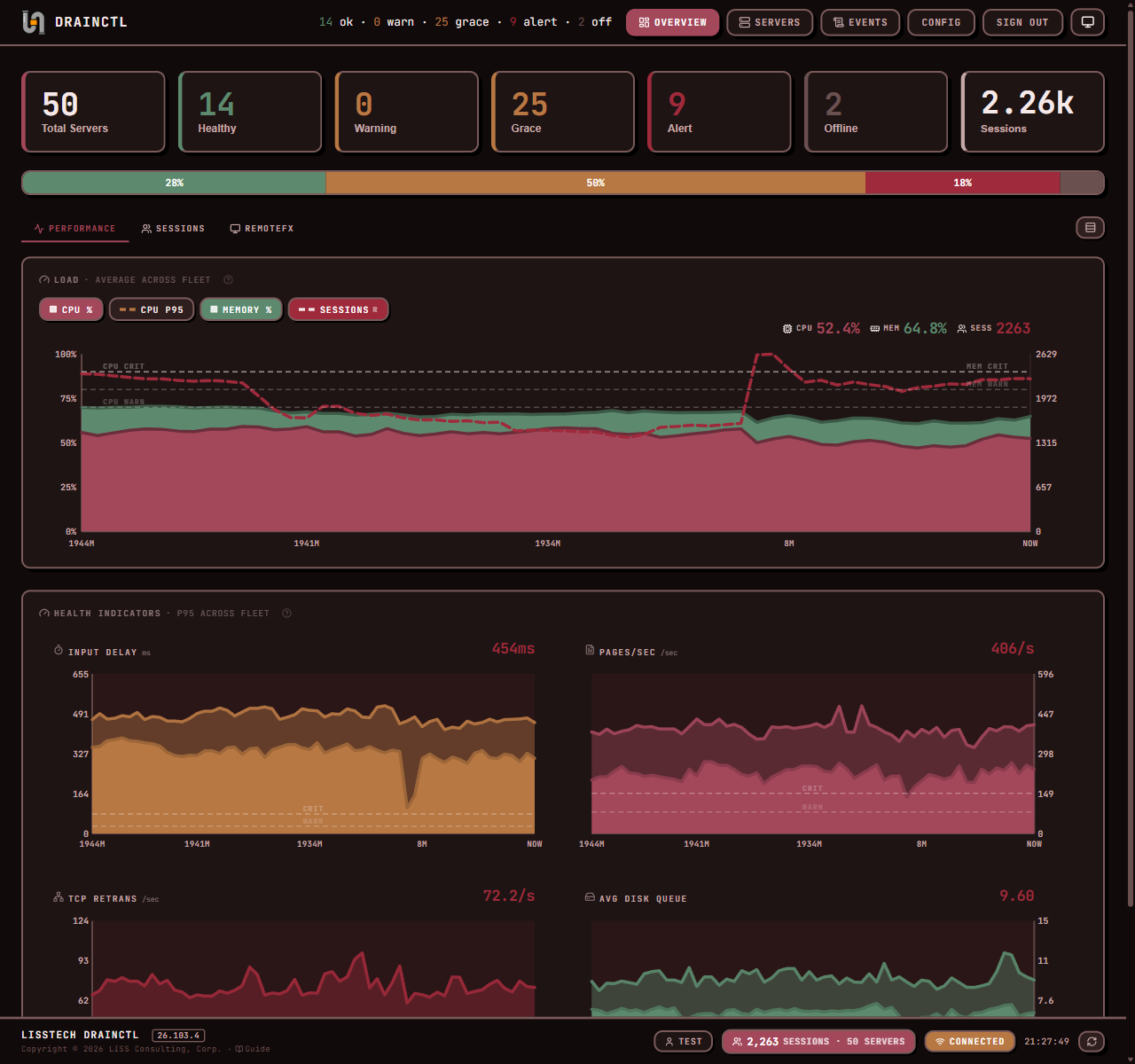
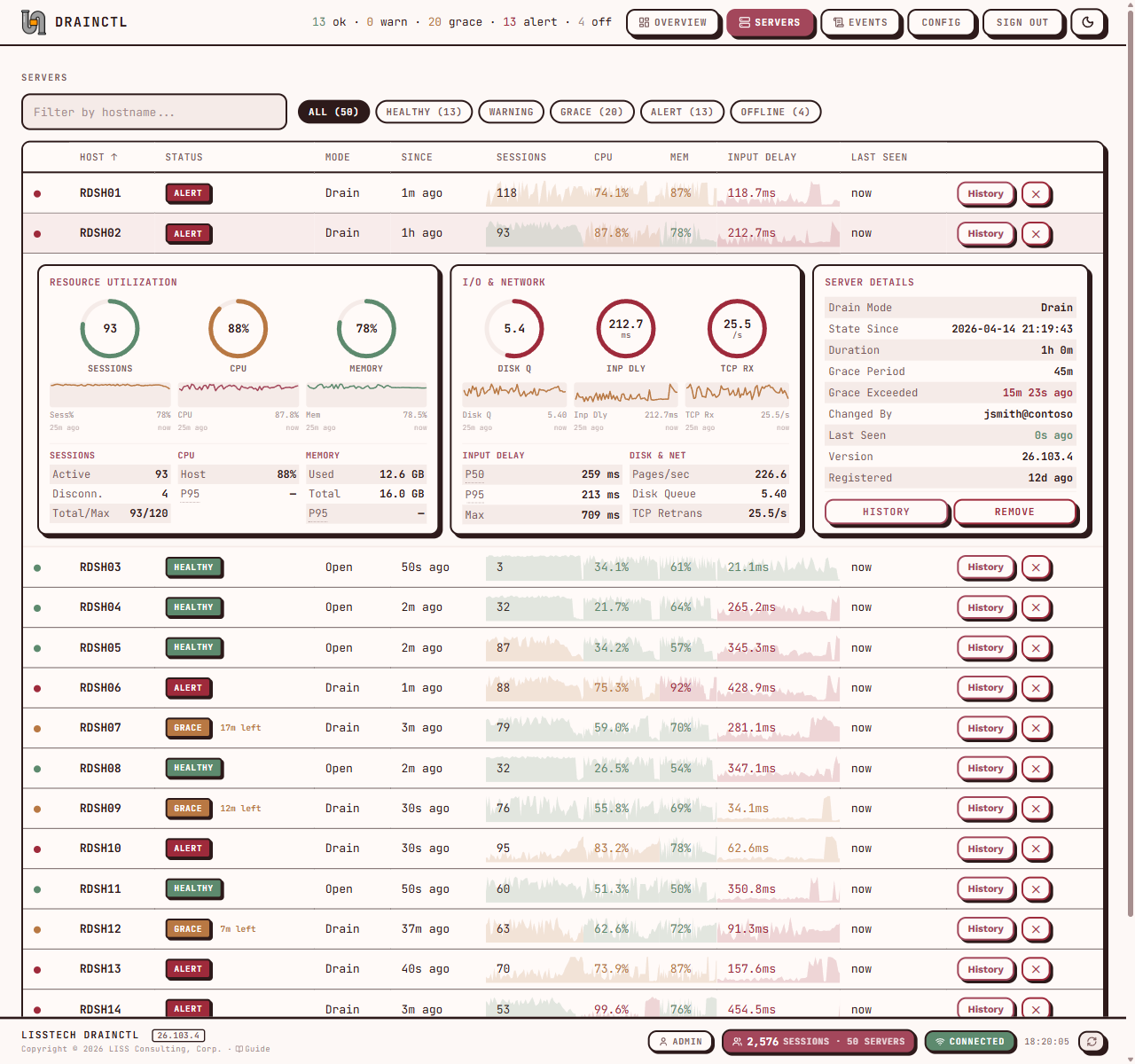
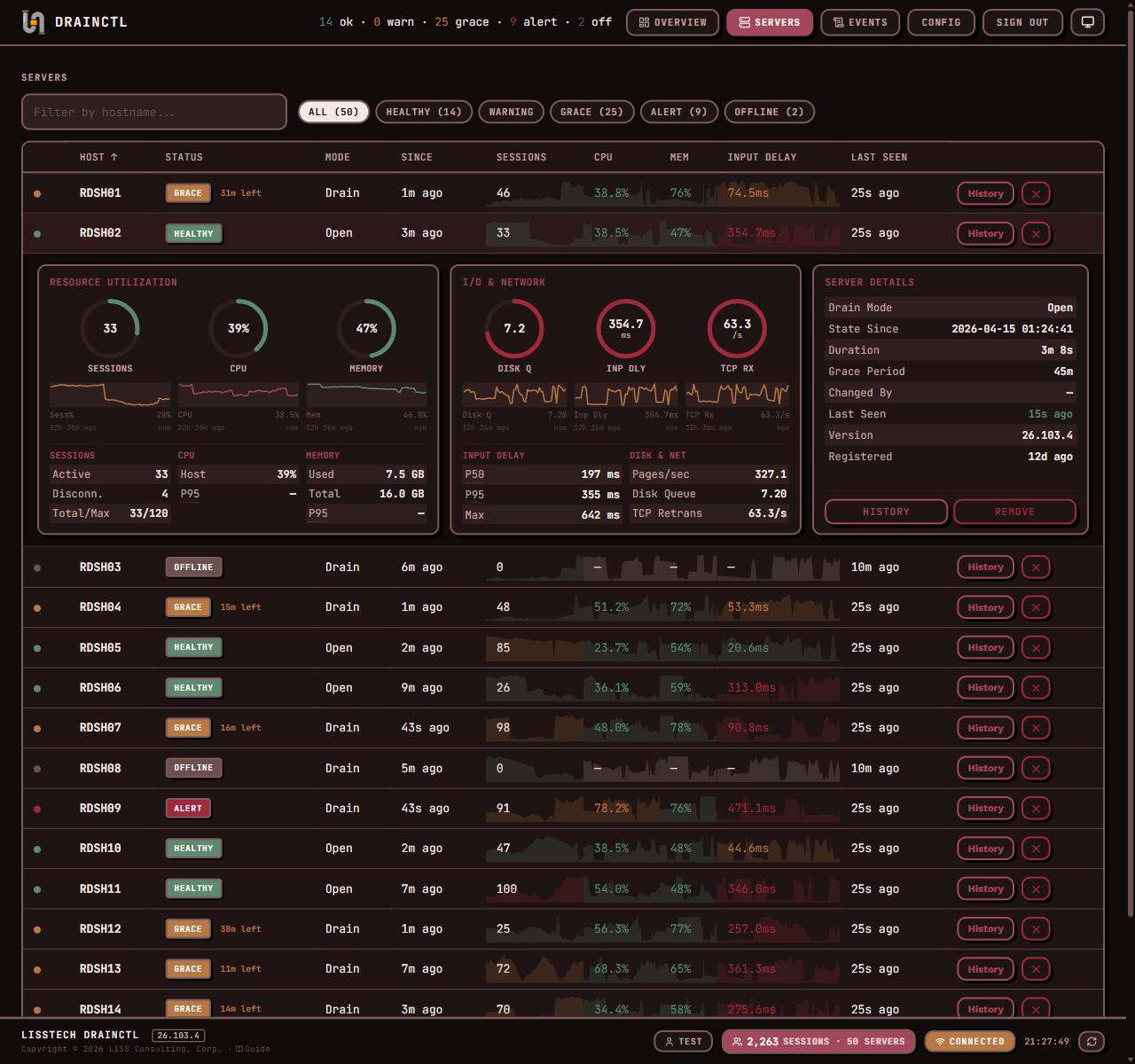
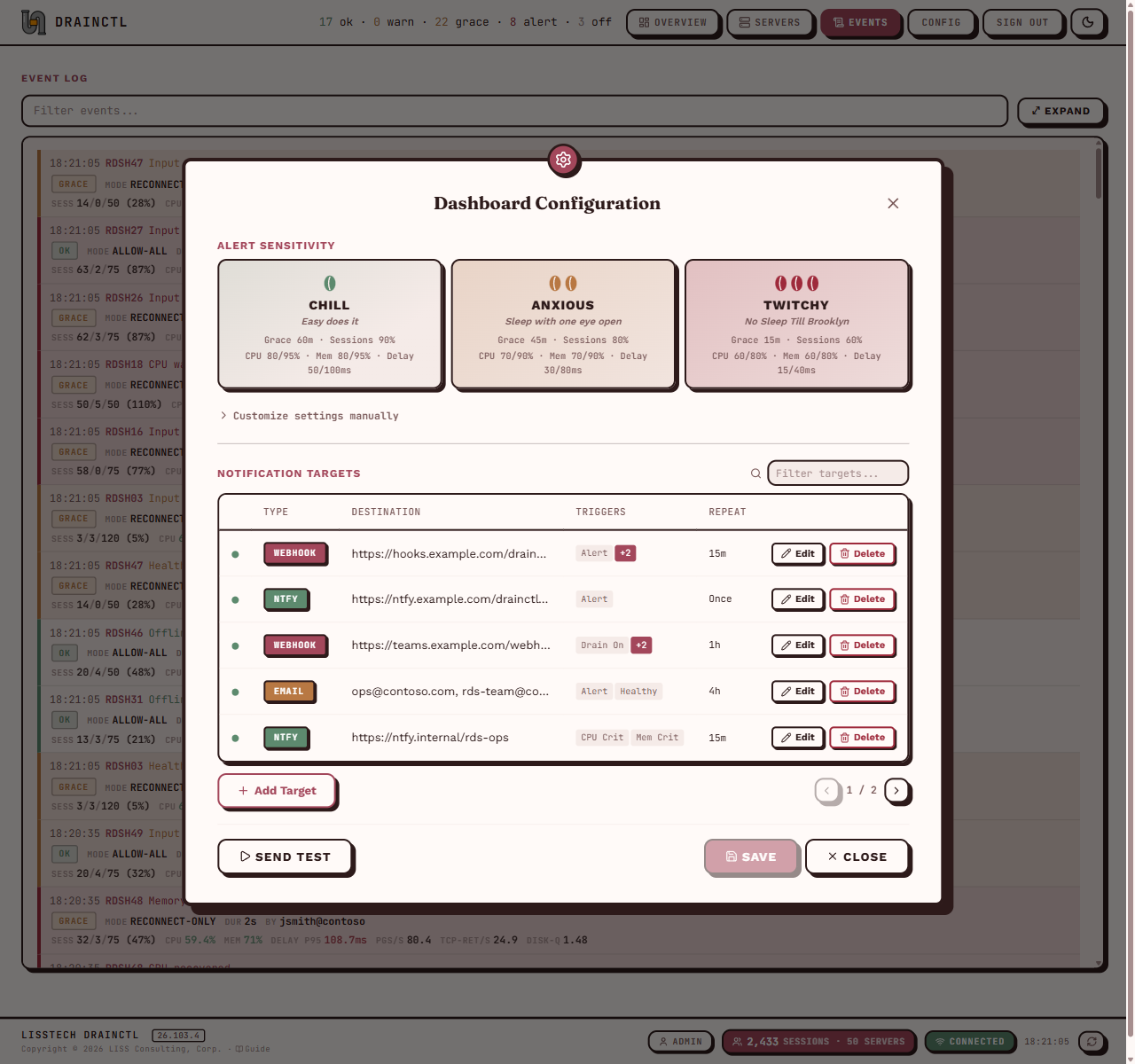
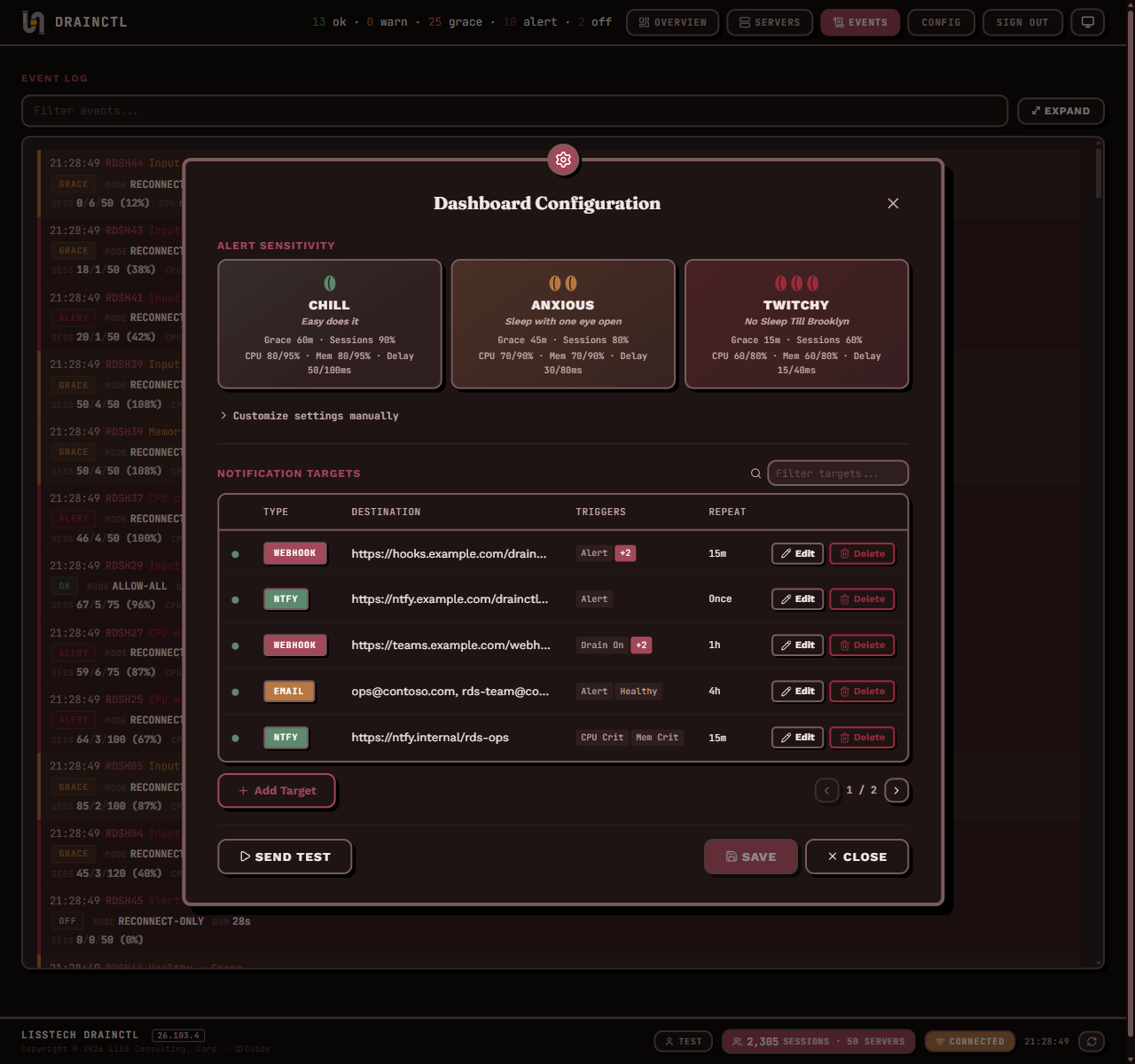
DrainCtl monitors every session host in your RDS farm — drain mode changes, active sessions, CPU, memory, input delay. One service, one dashboard, instant alerts. The change, who made it, and how long ago.
irm https://lissconsulting.github.io/LISSTech.DrainCtl/install.ps1 | iex